# 简介
- HashMap是一个散列桶(数组和链表),它存储的内容是键值对(key-value)映射
- HashMap采用了数组和链表的数据结构,方便继承了数组的线性查找和链表的寻址修改
- HashMap是非synchronized(但是在rehash和扩容的时候可能出现并发问题),所以HashMap很快
- HashMap可以接受null键和值,而Hashtable则不能(原因就是equlas()方法需要对象)
# 继承关系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
2
# 实现原理
- HashMap由数组+链表(+红黑树 1.8)来实现对数据的存储
- 详细可以看:HashMap原理深入理解 (opens new window)
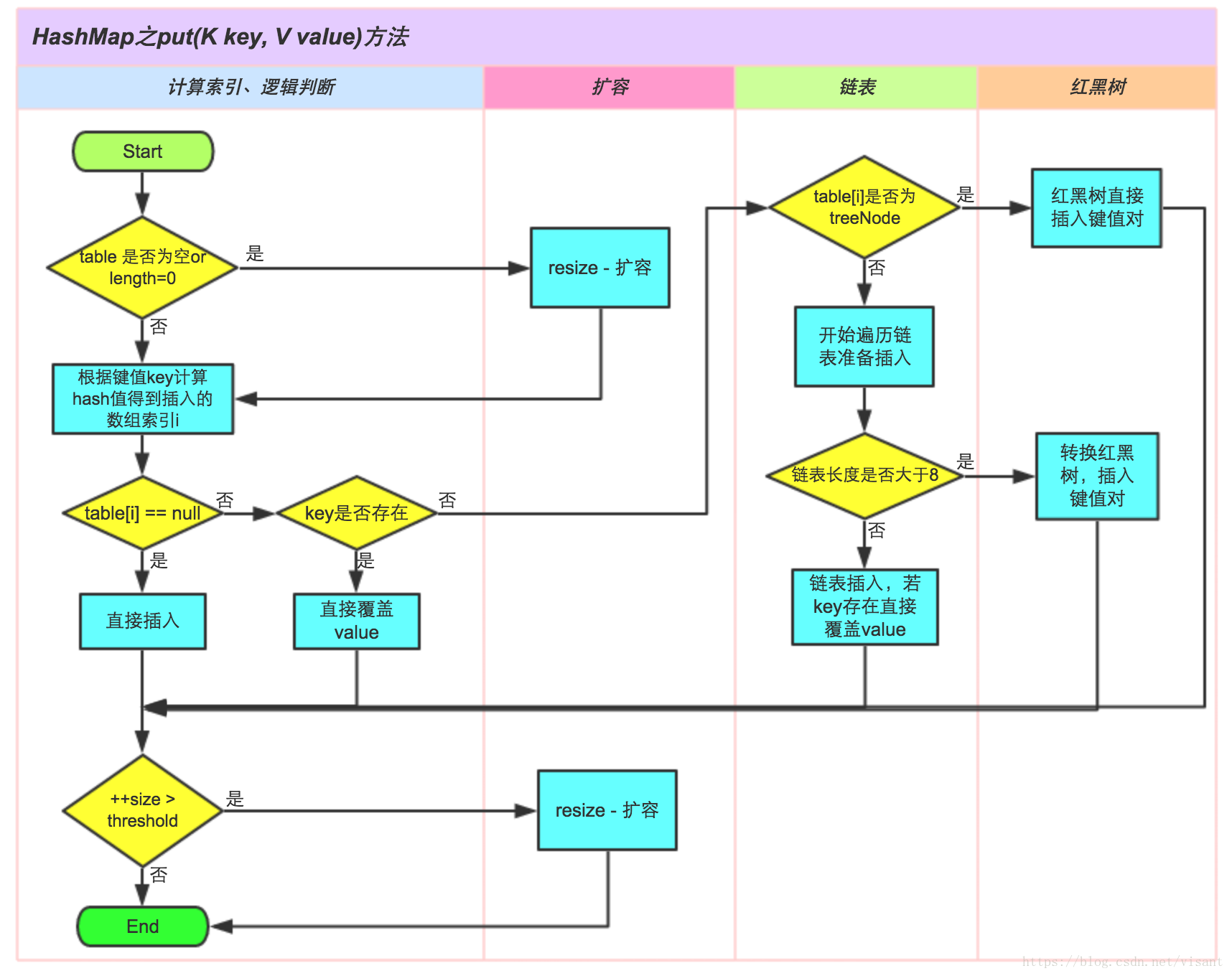
# 手写一个简单的HashMap
- 很简单,就是看一下HashMap源码中定义了什么属性、方法,然后我们写一个简单的类继承HashMap,挑其中几个重要的方法做出实现就好了
package com.eee;
import java.util.HashMap;
/**
* @className: MyHashMap
* @descripe: 模拟HashMap底层实现
* @author: zpj
* @date: 2019/6/7
* @version: 1.0
*/
public class MyHashMap<key,value> extends HashMap<key,value>{
//定义一个数组
private Node<key,value>[] table;
//初始化数组容量大小为 16
private static Integer CSHSZRL = 16;
//定义一个size,用来统计HashMap内个数
private int size = 0;
public MyHashMap() {
//创建对象的时候就初始化数组
table = new Node[CSHSZRL];
}
@Override
public int size() {
return size;
}
@Override
public value get(Object key) {
//算出这个节点是在哪个hash组
int hash = key.hashCode();
int index = hash % table.length;
//遍历
for(Node<key,value> node = table[index];table[index]!=null;node.getNext()){
//新元素和老元素一样的话
if(node.getK().equals(key)){
return node.getV();
}
}
return null;
}
@Override
public boolean containsKey(Object key) {
return super.containsKey(key);
}
/**
* HashMap的 put()方法
* @param key
* @param value
* @return 当put元素出现重复的时候,新元素覆盖老元素,返回老元素的value
*/
@Override
public value put(key key, value value) {
//算出这个节点是在哪个hash组
int hash = key.hashCode();
int index = hash % table.length;
//新增元素时,遍历老元素,和新元素比较
for(Node<key,value> node = table[index];table[index]!=null;node.getNext()){
//新元素和老元素一样的话
if(node.k.equals(key)){
value oldValue = node.v;
node.v=value;
return oldValue;
}
}
//当put第N个元素
addNode(key, value, index);
return null;
}
private void addNode(key key, value value, int index) {
//Node<key, value> node = new Node<>(key, value, null);//这个hash组是空的,put第一个元素
//table[index] = node;
//老节点对象
Node node = table[index];
//再把新的节点对象追加到原先节点头部,形成链表
table[index] = new Node(key,value,node);
//每增加一个元素,HashMap内 个数加1
size++;
}
@Override
public value remove(Object key) {
return super.remove(key);
}
/**
* 源码中定义了一个节点类对象,用来存放每个数据
* @param <K>
* @param <V>
*/
static class Node<K,V> {
private K k;
private V v;
//用来充当链表
private Node<K,V> next;
//可以传入新元素,然后构成链表
public Node(K k, V v, Node<K, V> next) {
this.k = k;
this.v = v;
this.next = next;
}
public K getK() {
return k;
}
public V getV() {
return v;
}
public Node<K, V> getNext() {
return next;
}
}
public static void main(String[] args){
MyHashMap<String,String> myHashMap = new MyHashMap<>();
for (int x=0;x<10;x++){
myHashMap.put(x+"貂蝉",x+"貂蝉配吕布");
}
myHashMap.put("8貂蝉","8貂蝉戏吕布");
System.out.println(myHashMap.get("8貂蝉"));
System.out.println(myHashMap.size());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
# HashMap的扩容机制 resize()
- 这一节是整个文章的重点,也是我学习的重点笔记,从这我也理解了为什么阿里规范手册中初始化HashMap的时候要指定大小。
# HashMap的负载因子
- 负载因子loadFactor保持在0.75f是在时间跟空间上达到一个平衡,实际上也就是说0.75f是效率相对比较高的
# 先说HashMap底层数组长度扩容为什么是2的幂次方数(其实就是为了使hash均匀分组)
只有当数组长度为2的幂次方时,hash&(length-1)才等价于h%length,即实现了key的hash定位,2的幂次方也可以减少冲突次数,提高HashMap的查询效率;
如果 length 为 2 的次幂 则 length-1 转化为二进制必定是 11111……的形式,再于 hash 的二进制与操作效率会非常的快,而且空间不浪费;如果 length 不是 2 的次幂,比如 length 为 15,则 length - 1 为 14,对应的二进制为 1110,再于 hash 与操作,最后一位都为 0 ,而 0001,0011,0101,1001,1011,0111,1101 这几个位置永远都不能存放元素了(这几个数最后一位都是1,化为10进制为1,3,5,9,11,7,13),空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费。
# 再来说HashMap的resize()
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize()。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过扩容是2的幂次方数,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
具体resize()的实现可以看:https://blog.csdn.net/u010890358/article/details/80496144 (opens new window)
# HashMap面试题
hashmap的主要参数都有哪些?
hashmap的数据结构是什么样子的?自己如何实现一个hashmap?
hash计算规则是什么?
说说hashmap的存取过程?
说说hashmap如何处理碰撞的,或者说说它的扩容?
== 答案 (opens new window) ==
针对 HashMap 中某个 Entry 链太长,查找的时间复杂度可能达到 O(n),怎么优化?
如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
为什么String, Interger这样的类适合作为键?
HashMap与HashTable区别,能否让HashMap同步?
== 答案 (opens new window) ==
HashMap 的 table 的容量如何确定?loadFactor 是什么? 该容量如何变化?这种变化会带来什么问题?
HashMap 的遍历方式及其性能对比
HashMap,LinkedHashMap,TreeMap 有什么区别?
HashMap & TreeMap & LinkedHashMap 使用场景?
为什么 ConcurrentHashMap 比 HashTable 效率要高,及ConcurrentHashMap?
== 答案 (opens new window) ==
